I like that this is basically Jupyter/Colab extended with an explicit cell dependence graph.
However, I think this needs some serious brand work to distinguish it from "visual programming," which multiple commenters have already confused it for.
Can you explain how this is not 'visual programming'? The interface seemingly allows for arbitrary code to be written and then graphically arranged in a dataflow-like format. If you mean that the fundamental elements of 'code' are the text inside each block, how is that fundamentally different than if each block was a black-box whose functionality was implemented using more blocks?
The emphasis of this project seems to be text based coding and visual description of dependencies at the cell level. Visual programming, at least according to wikipedia, refers to "manipulating program elements graphically rather than by specifying them textually," which this project does not do.
Not really in disagreement. However, I think that there is more than one level of granularity to this project. If you were to step back to the level where someone has a 'library' of these blocks of code (which seem to be able to present a 'black-box' style presentation) and then visually placing them and connecting the inputs and outputs of those various blocks is essentially visual programming within the meaning of the standard definition, like from Wikipedia.
The graphical elements themselves contain code (all visual programming systems work this way, even if the code is hidden). That's how new program elements are born.
Visual workflow languages work in a bunch of different ways. Nodes, in Blender, is a visual programming environment. Blockly is a visual programming environment. Those nodes in scratch have code behind them!
This is literally visual programming. Nodes connected with edges, nodes represent execution models that take inputs over in edges and write outputs over out edges. Everything right there in the video.
I love blueprints in ue4, but I think I don't like the look of this. It's weird to me that each node seems to be an arbitrary block of code. I've long wished for such a feature in unreal's blueprint visual programming language. However, I wouldn't want it to be the default. That kind of undermines the point of it all.
I would want 99% of nodes to be single function calls.
It makes more sense when you consider that this seems to be intended as an alternative to (Jupyter, etc.) notebooks, which are a major way of communicating methods in the data science segment of the Python community. Notebooks are linear sequences of cells with an arbitrary number of lines of code inside of them, and these cells can be executed one at a time in arbitrary order. A lot of the time the dependencies between these cells (whether it be conceptually, programmatically, etc.) is not linear. There therefore arises a lot of cognitive load in both trying to present (via comments, etc.) this structure as a writer and parse this structure as a reader.
I imagine that is the kind of problem this is meant to solve--drawing out and visually solidifying that structure. From this perspective, I'm not sure if there's much apparent value in making the 1 cell <==> 1 function call constraint the default.
Does anyone know of a more generalized framework for doing this kind of thing? I'd been meaning to write a framework kind of like this for some time, but never got around to it, and was hoping someone else would. This one unfortunately doesn't really check the important boxes, but it's a good start. I was hoping more for:
* Target language agnostic (this one seems to get mostly there) -- the nodes communicate data/logic flow, you then serialize/deserialize accordingly.
* Focus on data flow, not just execution -- IO from nodes, visual indicators of data types (colors or something)
* Capable of visually encapsulating complexity -- define flows within flows
* Ideally embeddable in web apps (e.g a browser/electron frontend or something)
These are pretty popular to embed in complex "design" oriented applications, especially ones that involve crafting procedures by non-programmers (e.g. artists, data scientists, etc). Examples where this is implemented that come to mind include Blender, Unity, and Unreal.
A core part of the fundamental design of each one of the successful implementations is that they allow efficient code to be crafted by people who don't think they understand code. Making it visual helps engage the brains of certain kinds of people. The "code as text" paradigm is spatially efficient, but it's like a brick wall for some people.
Having had to do that quite a few time, for instance for audio / control / visuals graphs in https://ossia.io as well as some proprietary stuff, I'm pretty much convinced now that it's easier to just whip up the graph data structure that fits the problem rather than trying to make a generic framework for that. Every time I tried to use a library of dataflow nodes it ended up not doing what I wanted the way I wanted, and rewriting something tailored to the use case was just much faster especially considering that you likely want user interface features which will be specific to what you are doing with your dataflow graph.
I've been working on a more general framework. Its not public, but I'm happy to chat with anyone who has a specific interest. At present it consists of the following elements:
* Language specification - code is stored as json.
* Compiler with an interpreter, Javascript, Typescript and Rust backends.
* Editor - not quite the classic style node editor. Our new design fixes a lot of the problems and complaints with the old style node editors, particularly information density and spaghetti layout.
* Language Server - provides type hints, etc to the editor.
* VSCode extension - integrates the editor and compilier into VSC.
Also of note, the language is statically typed, with generics. It handles loops, branches, and functions are first class. Recursion is not supported at present.
In time we also plan to build a LLVM backend, so an intermediate language won't be required. Currently the compiler is written in TS, but as it matures more we intend to make the language compile itself.
If you want to talk, seek me out (I work for Northrop Grumman Australia).
Hey, same about looking for a generalized framework, but I'd approach it from the other side.
I'm pretty okay with the general shape of code (a nested tree-type structure), but think the possible interactions are unnecessarily awkward by being forced into a text editor.
You ought to be able to effortlessly fold, move around and disable/enable blocks of code. There's not much of a point in allowing indentation or whitespace mistakes and it doesn't usually make much sense to select a part of a token (or often even just a token without the block it's attached to).
These issues can mostly be fixed by representing tokens and lines in a tree-like structure of nodes, for which useful editors already exist.
IDEs try to retrofit these things into their text model (the most advanced one I'm aware of being IntelliJ), with automatic indentation fixing and folding, but even the best attempts aren't even using 20% of the potential.
My most jarring example of how bad IDEs still are at this is folding + disabling (commenting out): When I comment out a block of code because I don't care about it that is folded because I don't care about it, it shows it back to me even though I don't want to see it because I double-don't care about it!
(Side note: I'm aware XCode doesn't do this, but it's far from general)
There is so much effort put into concepts, parsing and whatever, and everything uses trees, because that's the natural way of reasoning about code. Why are we still stuck interfacing with it through an awkwardly serialized version?
Not sure if fits the criteria but I have built CanvasGraphEngine[0] with the intent for it to be a visual programming tool for devs, meaning you still write code but it can be made into a node/graph so its easier to encapsulate code in a more visual manner.
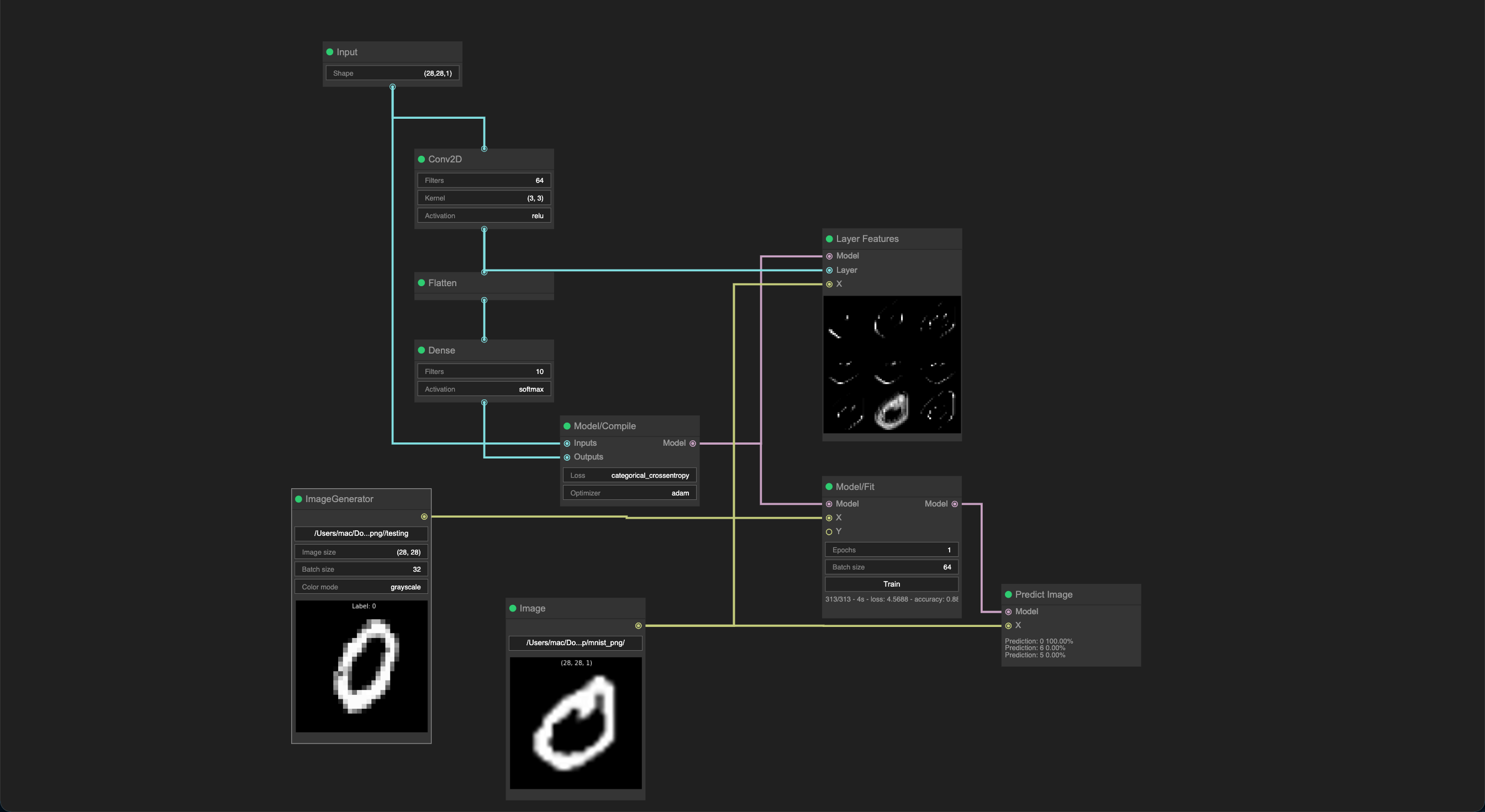
The main image[1] demonstrates how to train and predict a MNIST classifier with image generator and model building. Underneath the hood it connects to jupyter and each node wraps the necessary python code required for only that node. The jupyter version of it is not public but can be made if enough interest.
We are working in https://hal9.com which is language agnostic and allows you to compose different programming languages; however, we are focused at the moment at 1D-graphs but have plans to support 2D-graphs in the coming weeks.
If you want a demo or just time to chat, I'm available at javier at hal9.ai.
I worked on something very similar for my company about 10 years ago. The lesson I learned is it was much more robust to have a flow of data than a flow of code. I still think it's really cool though.
I am wondering if this could work for async programming. I once used a Discrete Event Simulation software that had an excellen graph based program editor that really showed the dependencies of the model very clearly. I later realized that Discrete Event Simulation is conceptually very similar to async programming. I would love to explore async programs as an animated graph. Anyone know if such a thing has been tried?
The modelling software I was thinking about is FlexSim by the way
LabVIEW uses a graphical language and gives very easy access to parallelism and message-based software architectures, though it can be quite difficult to learn and is plagued by lots of bad existing code. See OpenG [1] for some examples of good code.
I had worked on such a tool by extending pyqtgraph's flowcharts. Mainly executing the nodes when their input changes and showing a glowing box around the one running at the moment. Flowcharts supports multiple terminals already and I had added some custom nodes. Node execution must be delegated to a background thread so the gui is not blocked while the node executes. Doubleclicking a node shows a window for setting up the node. A custom class of nodes shows upon doubleclicking a simple python editor, upon execution the terminals get automatically the values of the variables carrying the same name as the terminals. It has been a lot of fun. I had used petl and pyspark for lazy loading so one could build large etl workflows.
> Link blocks to highlight dependencies, Pyflow will then automatically run your blocks in the correct order
This is a problem. If you require users to define dependencies for you, they will make mistakes and things will go wrong in ways that are incredibly difficult to debug. This is already a huge pain point with Jupyter notebooks, and they're only one-dimensional!
Have you considered going the route of Observable notebooks [1]? In an Observable notebook, each cell can export at most one variable. This means that the notebook can automatically determine dependencies statically, run cells in the correct order, and even show the user a viz of dependencies.
User conventions don't work, because there is no mechanism for enforcement other than "hope they remember!" I would say most users don't even know about this convention, given I work in an environment where notebooks are used heavily and have never heard of this. Because these mistakes are allowed to happen silently, they will happen, and it will almost certainly make the code harder to manage.
On top of that, Pyflow seems to rely on the user to define dependencies between blocks as well. This means that the user would have to both perfectly maintain the convention of one-variable-per-block, but also link every block that touches that variable going forward. Without ever making a mistake. It's such a well-defined graph problem that it's practically made for computers to handle, not fleshy people.
This is why tools are so important: they can impose constraints that allow you to act more freely elsewhere. When I change a cell in Observable or add a reference, I don't have to think. The engine handles dependencies for me, without fail. I can't make an entire class of errors, which means I can just focus on functionality.
Wait, what is it about exporting only one variable at a time that makes it possible to determine dependencies statically? Why not two variables? Or three? If you're determining dependencies based on variable names it seems like that would be possible.
You're right, it's more due to the fact that Observable requires you to explicitly export variables. However, limiting it to one has a couple advantages:
1. You don't recalculate other variables if only one needs to update. For example, if a cell exports two variables, and a dependency of one of them updates, you're forced to re-evaluate the whole cell.
2. I think the UX plays out simpler if you limit it to one variable. It basically reads like `myVar = {...}` at the top of the cell. It's a bit trickier if you try to support exporting multiple variables at once.
3. If you find yourself needing to tie several values together, you can still manage it by exporting a single dictionary value!
As a past user of Borland's ObjectVision, I would appreciate seeing this project developed far further... Similar to the Mindstorms programming interface, sometimes the object-based modular containment assists with abstraction/black box thinking.
Cool. Now the question is where does it run, and can we split blocks to serverless functions, or have a "cluster-mode" where each block can be executed on dedicated/specialized/available node.
My colleagues wrote PyF, using the same idea of code written in boxes that you link together. It saved all code blocks in an XML file.
We used it on financial data. One of our programs was so complex that we fell back on using a text editor to directly edit the XML instead of using the GUI.
The project was published on pypi but for some reason the source code was never published and it is in the same state since 2011, using python 2 and all. I left the place 2 years ago but my colleagues who still work there said it's still mission-critical. A kind of Cobol.
Can you imagine the popularity of a UI component driven version of this (along the lines of hypercard I guess), if web-based? I suspect the market for that would be MUCH bigger.
What do you mean by "UI component driven version of this" exactly? Like this, but to build UI components somehow?
FWIW, there are plenty of graph-based dev tools, especially in the data science & ML world, and they seem to only fit the nerdiest of audiences (like mine!) ; not very practical for most people.
Why would web-based ensure a much bigger market? If you have a one-click installation process, then a desktop app seems much more appropriate than a web page for a programming / data analysis tool.
It's surprising how the lazy node graph thing is spreading. I find it a superb model for most things (and, broken record moment: sidefx houdini or alias maya can show you how far one can go in this model. hint: james webb far).
Lazy is an odd choice of words? Lazy normally means that the data is only derived when needed, but most graph models work by pushing data wrapped as events through pipes?
'Push what's changed' is not a typical description of 'lazy' evaluation. As was said in a sibling comment, lazy is more of a demand-driven evaluation. However, I think you are more likely leaning into describing reactive programming paradigms. the description in parent is not exactly describing reactive, but it is certainly in the 'wheelhouse' of reactive programming. Typically, node based compositing is definitely reactive, and is most often lazy as I discuss in a sibling post.
Lazy is usually used to mean demand-driven, as opposed to input-driven, in my experience, so exactly the opposite of this, but different people mean different things. (Did a lot of my PhD on dataflow.)
I think, as parent implied, this is more of a semantic issue than any substantial disagreement. You are, in most instances of compositing systems of this style, correct that the computations are typically not triggered unless some view node is utilized. Additionally, if your view node is in the middle of some chain of nodes, only those nodes before the view would actually be performed. This is somewhat similar to the usage of lazy in regards to the operational semantics of programming languages. Again, as parent states, lazy 'evaluation' is basically demand driven computation. Python is not a lazy language, it utilizes eager evaluation by default. So in the sense that Pyflow seems to be a sort-of 'visual programming'/dataflow frontend for Python, I would assume that it is eagerly evaluating the code in the order of dependencies as determined by the graph.
and you know it got me thinking, languages are trees, and haskell tweaks it into DAG (shared call-by-need) .. evaluated one way, but in the context of UIs you get a larger graph set it seems, where any node can evolve and the consistency of the whole graph needs to be rebalanced. Just thinking out loud.
Sorry - I didn't mean to say that you were wrong, I was just confirming if your thing with a different name than I was used to was the same as a thing in my head.
This is very close to what I wish ObservableHQ/Pluto.jl had. Their reactive model already allows you to branch off, connect arbitrary nodes and re-run only what's needed, but the visual ordering of the cells is still very inflexible.
Very unreal engine blueprint-like. I always wondered why that caught on with game engines but (partial) visual programming isn’t used by folks pretty much anywhere else besides some introductory programming courses/tutorials or kids projects. Personally, I think the abstractions could be useful for other domains like building/prototyping ML models too but so far no user demand for the tools.
This form of visual programming has been used in 3D modeling and visualization industries for 15+ years [0-3]. It's an excellent gateway to real programming, but any complexity quickly overwhelms the visual organization of nodes.
UE blueprints make the game engine api discoverable. Doing low level code in bps sucks. But stringing together engine calls feels good.
edit: basic math is a good example.
(a+b) / c * 3 + 7 is very easy to write out in code, but is going to include the following nodes to express
a
b
+
/
c
*
+
7
and lines between them to connect data and functions. Gross. Ue4 technically has a mathematical expression node for this specific case but its one of the more painful things without it.
I am building a web application (FastAPI+PostgreSQL+Angular) that includes some user scripting. Any suggestions for libraries that do this sort of thing, but have an option to be integrated into existing apps?
Ugh. Yet another visual ML programming tool. They look great for demos. And are a complete disaster when you try to do real work. At any real-world level of complexity, managing boxes and arrows is totally untenable, and you need code. All the world's coding tools are great for code. Doing git diffs or code reviews on boxes and arrows just doesn't work.
This will join a crowded graveyard of visual ML tools along with the likes of ML.Net or Azure ML Studio Whatever, KNIME, CreateML, PyCaret, Teachable Machine, etc etc etc.
The pattern is very predictable. Nice demo. Excitement hits real-world problem. Complexity. Implosion.
It looks like the graphical part is optional. You could just have one big node that was a Python program. Hopefully that means you could use the arrows and boxes only where they are natural. They'll at least be natural to impose at the top level of your program. They might also be useful at lower levels, if it's possible to make a functional abstraction out of a signal diagram.
Diffs will still be a problem though. I wouldn't touch this stuff with a ten foot pole.
It's not PyQt but QtWidgets in C++ directly - https://ossia.io/score-web uses QGraphicsView for the central view. It's not been updated to Qt 6 which fixes a lot of drag'n'drop-related bugs yet so the experience is icky.
{kind=link}